How to Read Heat Map in Python
Heatmap Basics with Seaborn
A guide for how to create heatmaps with Matplotlib and Seaborn
![]()
The idea is straightforward, replace numbers with colors.
Now, this visualization style has come up a long way from elementary color-coded tables. It became widely used with geospatial data. Its normally applied for describing the density or intensity of variables, visualize patterns, variance, and even anomalies.
With and so many applications, this unproblematic method deserves some attention. This article volition go through the nuts of heatmaps and come across how to create them using Matplotlib and Seaborn.
Hands-on
We'll use Pandas and Numpy to aid us with information wrangling.
import pandas every bit pd
import matplotlib.pyplot as plt
import seaborn equally sb
import numpy as np The dataset for this example is a time series of strange substitution rates per U.S. dollar.
Instead of the usual line nautical chart to represent the values over time, I want to visualize this information with a color-coded table, having the months as columns and the years every bit rows.
I'll try sketching both the line chart and the heatmap to understand how this will await.
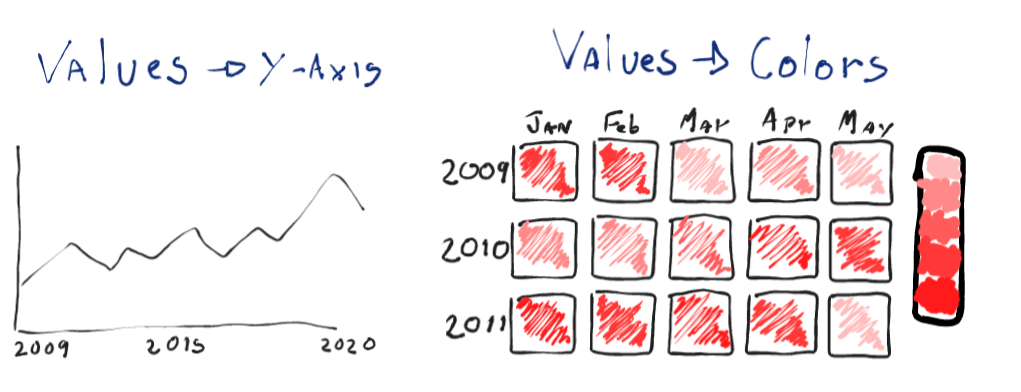
Line charts would be more constructive in displaying the data; it'south easier to compare how higher a signal is in the line than to distinguish colors.
Heatmaps will have a higher touch as they are not the conventional way of displaying this sort of information. They'll lose some accuracy, especially in this case, since we'll need to amass the values in months. Simply overall, they would nevertheless be able to display patterns and summarize the periods in our information.
Let'due south read the dataset and rearrange the data according to the sketch.
# read file
df = pd.read_csv('data/Foreign_Exchange_Rates.csv',
usecols=[1,7], names=['Date', 'CAD_USD'],
skiprows=1, index_col=0, parse_dates=[0]) For this example, nosotros'll use the columns 1 and 7, which are the 'Time Serie' and 'CANADA — CANADIAN DOLLAR/U.s.$'.
Let's rename those columns to 'Appointment' and 'CAD_USD', and since we're passing our headers, we as well need to skip the first row.
We besides demand to parse the first column, so the values are in a DateTime format, and we'll define the date as our index.
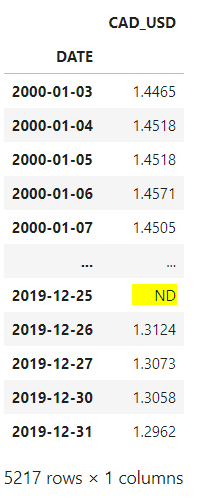
Allow's make sure all our values are numbers, and remove the empty rows also.
df['CAD_USD'] = pd.to_numeric(df.CAD_USD, errors='coerce')
df.dropna(inplace=True) We demand to aggregate those values past month. Let'southward create separate columns for month and year, and so we grouping the new columns and get the mean.
# create a copy of the dataframe, and add columns for month and year
df_m = df.re-create()
df_m['calendar month'] = [i.calendar month for i in df_m.index]
df_m['year'] = [i.year for i in df_m.index] # group past calendar month and year, get the boilerplate
df_m = df_m.groupby(['calendar month', 'twelvemonth']).mean()
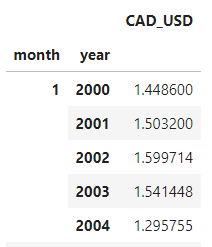
All that's left to do is unstack the indexes, and we'll have our table.
df_m = df_m.unstack(level=0) 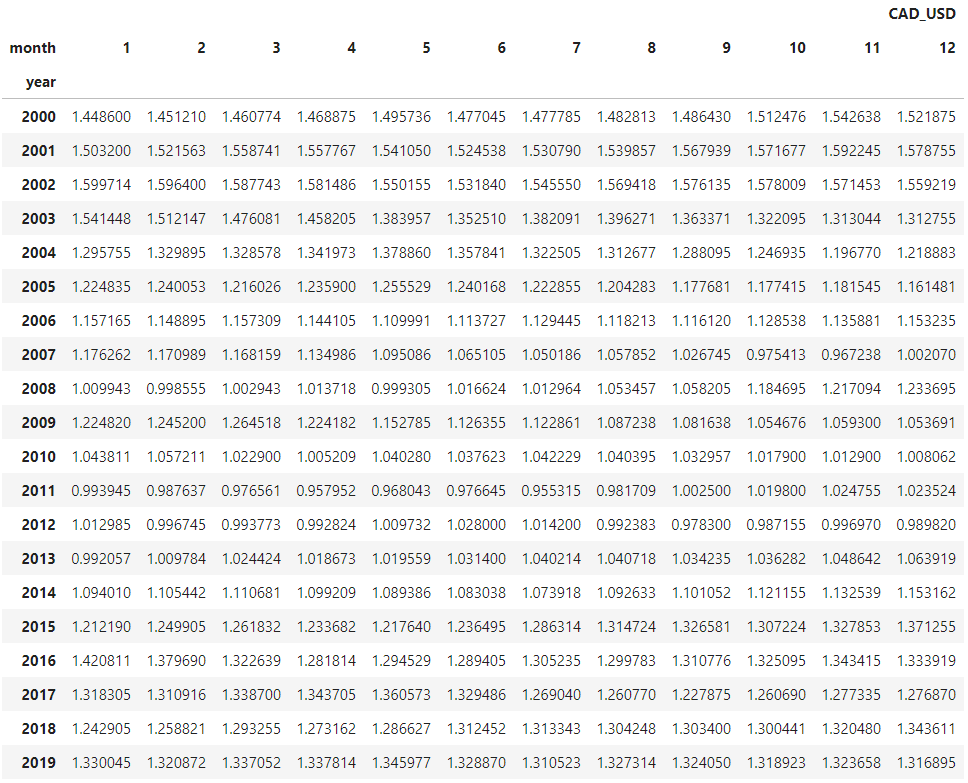
Colormaps
Everything is in place. Now we tin use Seaborn's .heatmap and plot our first nautical chart.
fig, ax = plt.subplots(figsize=(11, nine)) sb.heatmap(df_m) plt.bear witness()
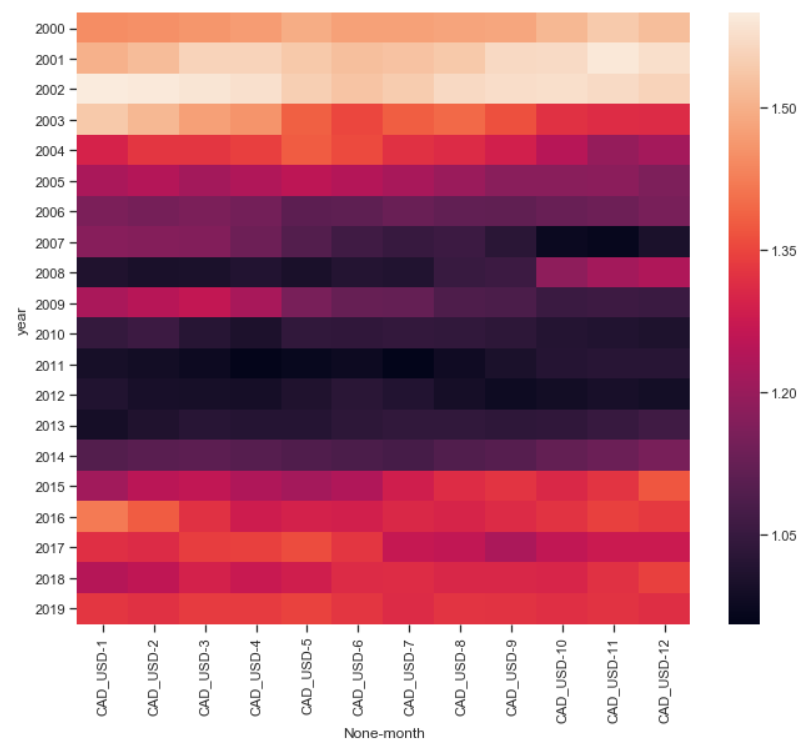
Alright, at that place's lots to do before this visualization is ready.
The colors are the most disquisitional part of our chart, and the colormap is a fleck overcomplicated. Nosotros don't need that; instead, we could utilize a sequential cmap with only 2 colors.
Nosotros tin can too make the limits of the colormap explicit by defining vmin and vmax. Pandas .min and .max can assist u.s. effigy out what are the best values for those.
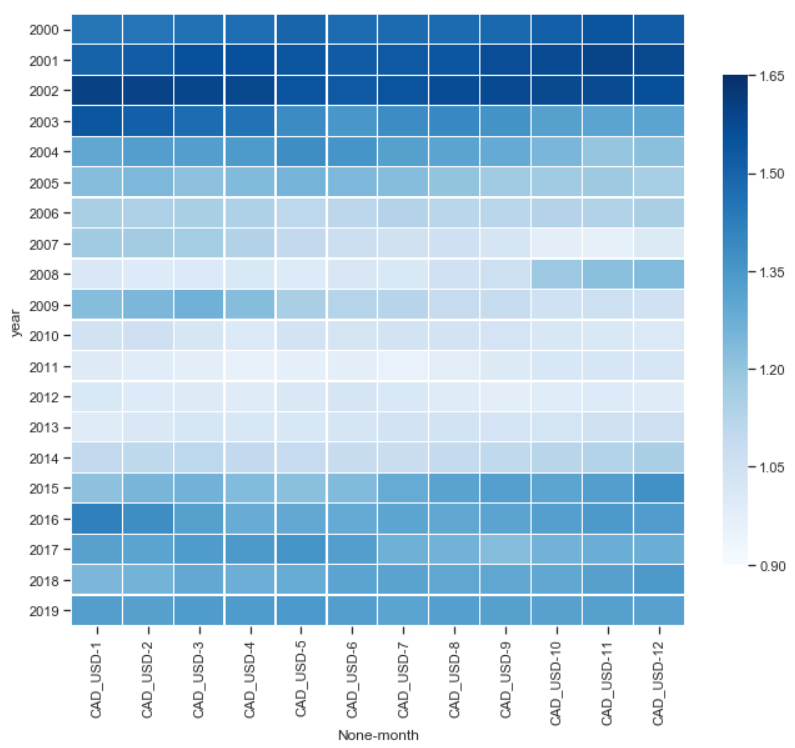
fig, ax = plt.subplots(figsize=(11, ix)) # plot heatmap
sb.heatmap(df_m, cmap="Blues", vmin= 0.nine, vmax=ane.65,
linewidth=0.three, cbar_kws={"compress": .8}) plt.show()
Customizing
In that location are lots of other arguments to be explored with .heatmap.
For instance linewidth defines the size of the line betwixt the boxes, and we can even pass arguments straight to the color bar with cbar_kws.
The colors expect good, and at present we tin can move our attention to the ticks. I don't call back CAD_USD-1 is the right name for Jan. Permit'southward replace them with some friendlier text.
Moving the ticks to the peak of the chart would meliorate the visualization and arrive look more like a table. We can likewise eliminate the x and y labels since the values in our axis are pretty self-explaining, and the title would also make them redundant.
# effigy
fig, ax = plt.subplots(figsize=(11, 9)) # plot heatmap
sb.heatmap(df_m, cmap="Dejection", vmin= 0.9, vmax=ane.65, square=True,
linewidth=0.iii, cbar_kws={"compress": .viii}) # xticks
ax.xaxis.tick_top()
xticks_labels = ['Jan', 'February', 'Mar', 'April', 'May', 'Jun',
'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
plt.xticks(np.arange(12) + .5, labels=xticks_labels) # axis labels
plt.xlabel('')
plt.ylabel('') # championship
title = 'monthly Average exchange rate\nValue of ane USD in CAD\n'.upper()
plt.title(title, loc='left') plt.show()

In that location's one last argument I passed to the heatmap, which is foursquare. That will brand the cells of our matrix in a square shape regardless of the size of the figure.
Overall, it looks practiced. We tin can see that the U.S. dollar was about l% higher than the Canadian in the early 2000s, which started changing around 2003. This lower dollar was sustained until late 2014, with some variation during the financial crunch of 2008.
By 2015 it had stabilized around 1.20~1.40, with relatively slight variation in the monthly averages until 2019, the cease of our records.
Correlation Matrix
For the post-obit example, I'll become through a correlation matrix to see some more functions of Seaborn's heatmap.
The dataset is a sample of eighty different kinds of cereal, and I want to wait at their compositions.
To build the correlation matrix, we can utilise Pandas .corr().
# read dataset
df = pd.read_csv('data/cereal.csv') # go correlations
df_corr = df.corr() # irrelevant fields
fields = ['rating', 'shelf', 'cups', 'weight'] # driblet rows
df_corr.drop(fields, inplace=True) # drib cols
df_corr.drop(fields, axis=ane, inplace=True)
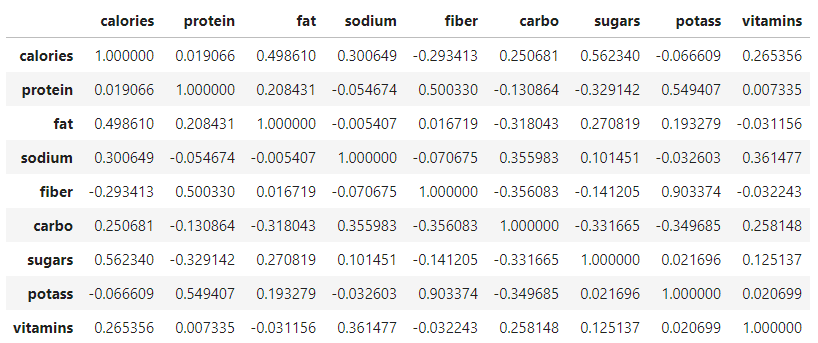
In that location's lots of redundancy in a correlation matrix; the upper triangle of the tabular array has the same information as the lower.
Masks
Luckily we can use masks with Seaborn's heatmap, and Numpy has the functions to build one.
np.ones_like(df_corr, dtype=np.bool) 
Numpy .ones_like can create a matrix of booleans with the same shape as our data frame, while .triu volition render only the upper triangle of that matrix.
mask = np.triu(np.ones_like(df_corr, dtype=np.bool)) 
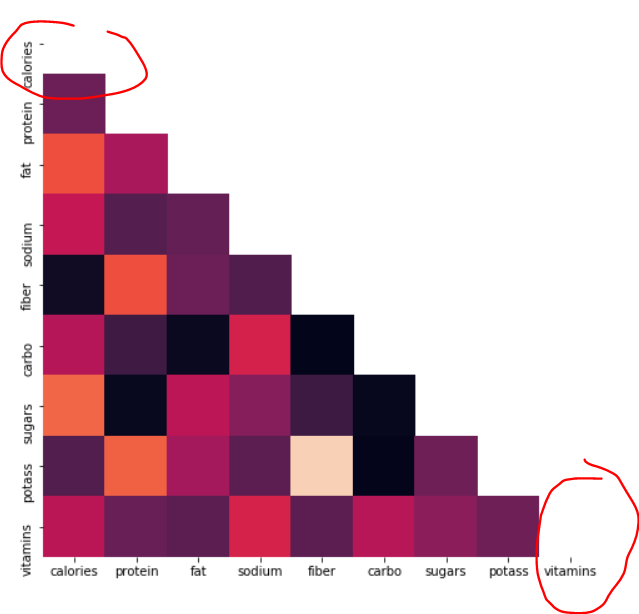
The mask can assist, but in that location are all the same two empty cells in our matrix.
At that place'due south nothing incorrect with it. Those values can add to the symmetry of our plot — That is to say, it's easier to know two lists are the same if they start and end with the same values.
If similar me, you're bothered with that, you lot can filter those out when plotting.
fig, ax = plt.subplots(figsize=(10, 8)) # mask
mask = np.triu(np.ones_like(df_corr, dtype=np.bool)) # adjust mask and df
mask = mask[1:, :-1]
corr = df_corr.iloc[one:,:-i].copy() # plot heatmap
sb.heatmap(corr, mask=mask, annot=True, fmt=".2f", cmap='Dejection',
vmin=-1, vmax=ane, cbar_kws={"shrink": .8}) # yticks
plt.yticks(rotation=0) plt.show()
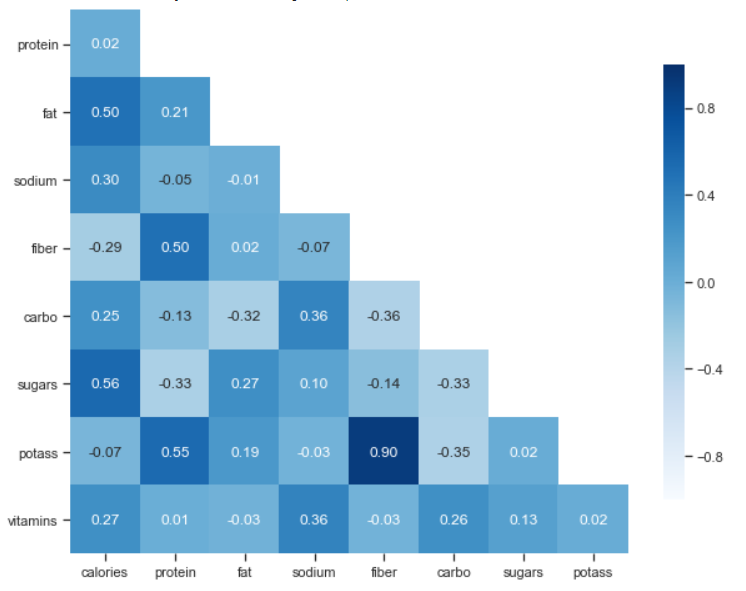
Cool, the only affair not mentioned was the annotations. We can set those with the parameter annot and we can pass a formatting function to information technology with fmt.
Diverging Palette
We still need a title, and the ticks would wait better with an upper case, but that's non the priority yet.
Correlations range from -1 to i, so they have ii directions, and in this case, a diverging palette works better than a sequential 1.

Seaborn has an efficient method for that, chosen .diverging_palette, it serves to build the colormaps we need with one color on each side, converging to another colour in the center.
That method uses HUSL colors, so you need hue, saturation, and lightness. I used hsluv.org to select the colors of this chart.
fig, ax = plt.subplots(figsize=(12, 10)) # mask
mask = np.triu(np.ones_like(df_corr, dtype=np.bool)) # adjust mask and df
mask = mask[1:, :-i]
corr = df_corr.iloc[1:,:-i].re-create() # colour map
cmap = sb.diverging_palette(0, 230, xc, 60, as_cmap=Truthful) # plot heatmap
sb.heatmap(corr, mask=mask, annot=True, fmt=".2f",
linewidths=5, cmap=cmap, vmin=-ane, vmax=one,
cbar_kws={"shrink": .8}, square=True) # ticks
yticks = [i.upper() for i in corr.index]
xticks = [i.upper() for i in corr.columns] plt.yticks(plt.yticks()[0], labels=yticks, rotation=0)
plt.xticks(plt.xticks()[0], labels=xticks) # championship
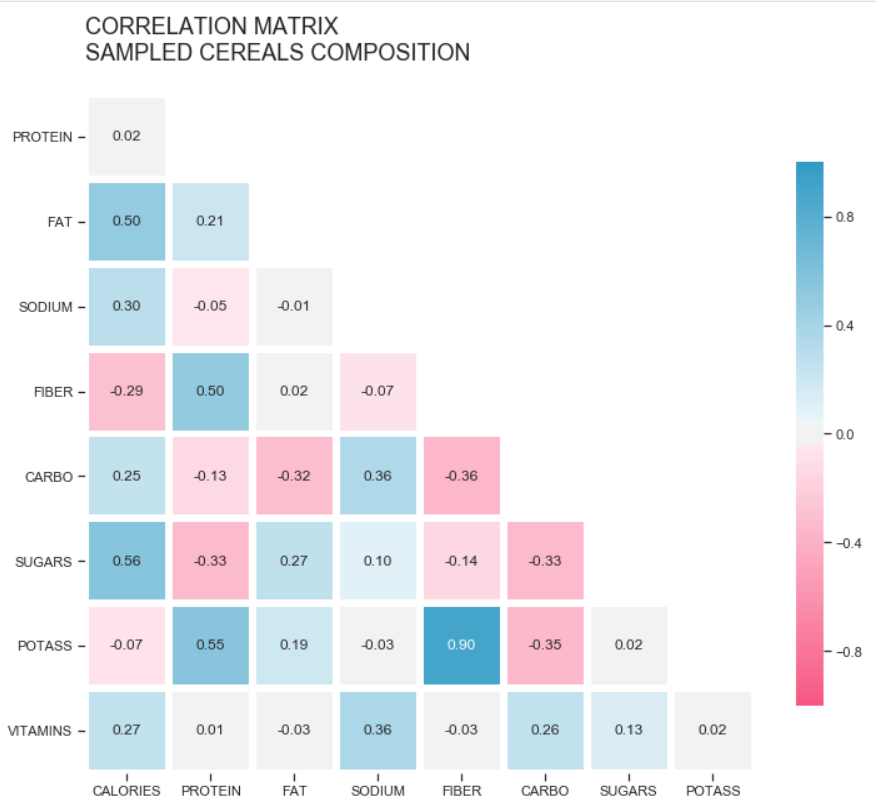
title = 'CORRELATION MATRIX\nSAMPLED CEREALS COMPOSITION\n'
plt.title(title, loc='left', fontsize=eighteen) plt.testify()

Pretty cool, we congenital a beautiful visualization for the correlation matrix. At present it's easier to see the well-nigh significant correlation coefficients, like Fiber and Potassium, for case.
Density
Usually, after a correlation matrix, nosotros get a ameliorate look at the variables with a potent relationship.
In this case, we don't have likewise much data to wait into, then a scatter plot would be enough to start investigating those variables.
The problem with besprinkle plots is that they tend to become hard to read with too much data, every bit the points start to overlap. That's when heatmaps get dorsum in the scene to visualize density.
fig, ax = plt.subplots(1, figsize=(12,8)) sb.kdeplot(df.potass, df.fiber, cmap='Blues',
shade=Truthful, shade_lowest=Imitation, clip=(-1,300)) plt.scatter(df.potass, df.cobweb, color='orangered')
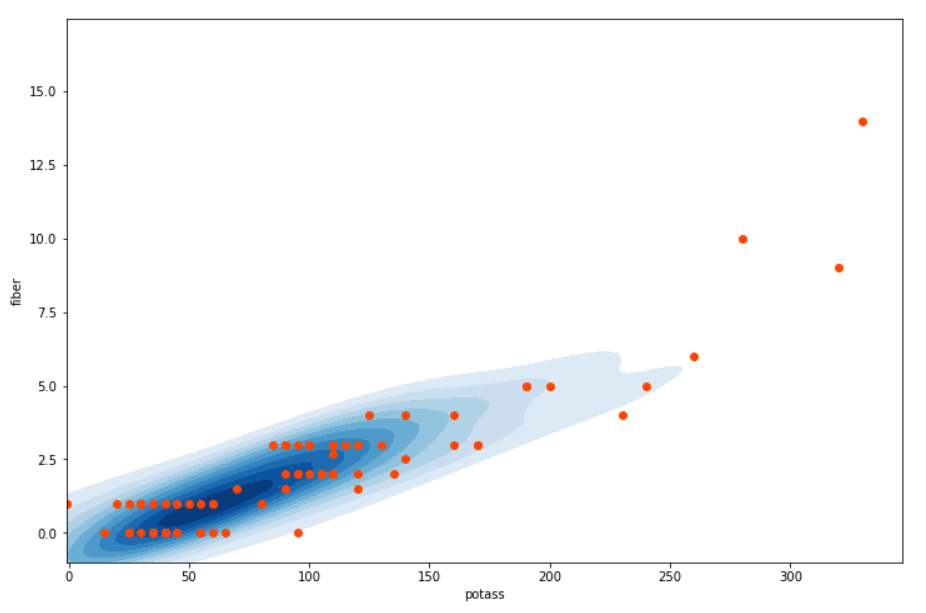
If you're interested in learning more than about KDE, I suggest yous get a look at Matthew Conlen's commodity about this topic.
Well, nosotros explored most of the basics in heatmaps and looked at how they tin can increase complexity with color maps, confined, masks, and density estimations.
Thank you for reading my article. I hope you enjoyed it.
Here y'all can find more tutorials on DataViz with Python.
lanierpurabbighty.blogspot.com
Source: https://towardsdatascience.com/heatmap-basics-with-pythons-seaborn-fb92ea280a6c
0 Response to "How to Read Heat Map in Python"
Post a Comment